
Hari Recipes
Welcome to The Internet
The internet sucks. I think everyone feels the same level of disgust when going online in 2024 and seeing the enormous volumes of content, most of which is garbage, inaccessible, inconvenient, or locked behind walled gardens.
The modern internet is an “ecosystem” in the same way that a landfill is an ecosystem. We are like seagulls, picking through mountains of trash looking for slivers of useful information, while around us, bulldozers are piling up even more trash the whole time. My hope is to build things that are the opposite– useful and simple.
Hari Recipes is a web app I built in <80 person-hours of work. It is a simple app that provides quick, (somewhat) accurate semantic search over a database of 300,000 recipes scraped from the internet. It is designed to be self-hosted, or hosted on small virtual machines with little to no configuration. It is also designed to be hackable (stupidly simple). Each part of the app, from the code used to crawl the recipe websites, to the code for semantic search, is able to be played with and run in isolation.
The goal here is to disentagle you dear reader, and anyone else who you know that likes cooking, from every recipe website. Starve the beast by not playing any ads or giving them any traffic. Host it yourself and use it on your wifi, or host it in the cloud or a RaspberryPi and share the link with your mom so she can use it.
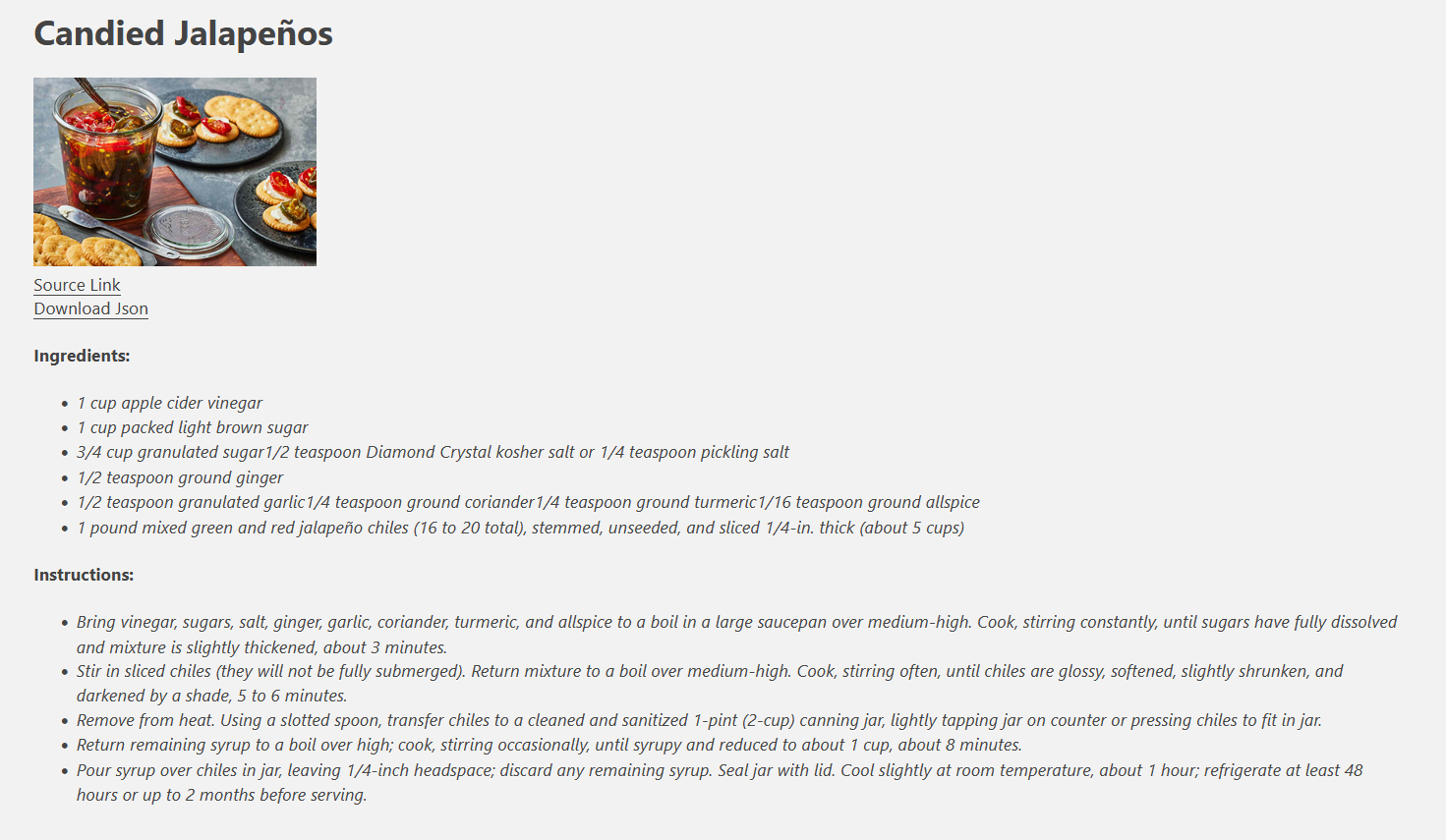
Here is an actual example of me looking for a sweet tea recipe on the internet on my phone.
Here’s what the networking tab looks like for that page:
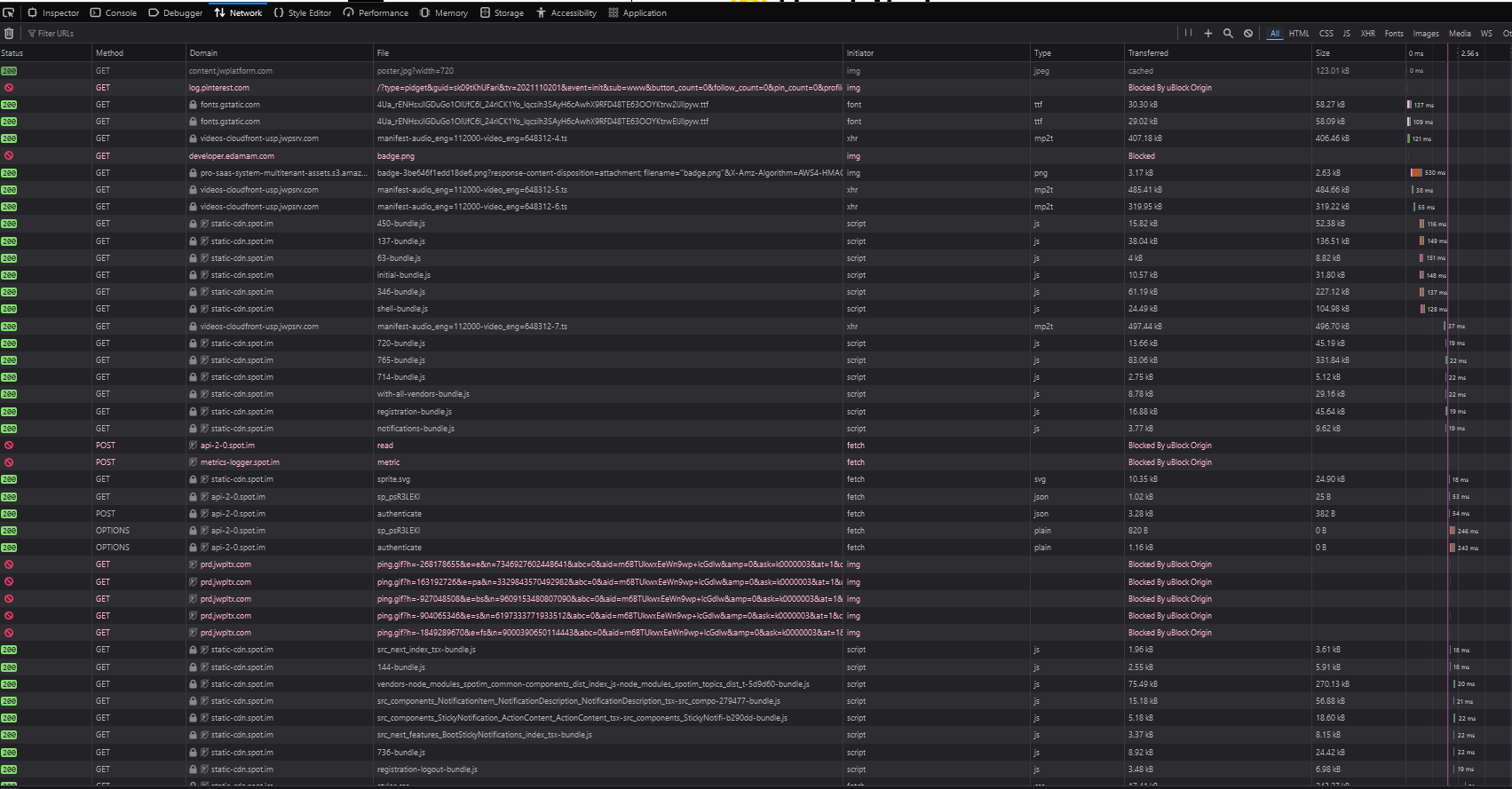 Who does this help? What problem does this solve? How many hours of human labor and kilowatt-hours of energy were spent making this shit, which is not only useless, but actively antagonistic to users? Cancer is the only word I can think of to describe this. Cells that have forgotten their original purpose and now just exist to propagate themselves.
Who does this help? What problem does this solve? How many hours of human labor and kilowatt-hours of energy were spent making this shit, which is not only useless, but actively antagonistic to users? Cancer is the only word I can think of to describe this. Cells that have forgotten their original purpose and now just exist to propagate themselves.
Here is a query for sweet tea on hari.recipes
I am not a very clever person. But even the most mediocre developer can solve real problems. I believe hari.recipes is solving a real problem, and it took very little of my time to make.
The rest of this post is about how I built the project. But the main takeaway I would like for everyone to have is that we can starve the beast, even just a little bit at a time. If everyone solves small problems and share those solutions with their friends, maybe we can reclaim a little bit of the “good internet”.
Here are some websites that actually provide value, which I took inspiration from:
Round House Overalls
RockAuto
Maestro Spanish
Note:
Not all recipe websites are as bad as the one I linked. Many of them are very well-curated and run by well-meaning individuals. Practice discretion between content farm recipe websites, and ones like this
Ideation
Earlier this year I migrated all of my personal notes off of Notion and onto a github repo that uses Obsidian as a markdown renderer. Migrating away from Notion had some issues which I speculate might be a form of vendor lock-in, but eventually I got it done. I started using Obsidian for note-taking very frequently, and started using it a lot for saving recipes.
Note:
I noticed that manual curation of recipes was actually far superior to just bookmarking them in the browser. I could correct errors in the original recipe, add clarifications, substitutions, etc. I think that the difference is one of ownership. I figured that this pattern of copying down recipes into markdown and saving them locally could be automated, and so the project began.
Note:
Ben Awad (a very funny software dev/content creator) already had the same idea about recipe curation and ownership. However, it is a paid app that requires an account. Unfortunately I consider this solution to be equally as contrived as the problem it solves (no offense to Ben, you gotta make a bag somehow, I respect the hustle). But, I feel like I would be taking undue credit for the idea if I didn’t mention it here.
Finding Recipes
Finding the recipe scrapers Python package meant that the project was not only going to be doable, but a piece of cake. The hard part was already solved for me.
Most recipes are stored in a script tag with the type application/ld+json. There are a couple of issues here for our webcrawler.
- To tell if a page contains a recipe, we have to scrape the page for every script tag, then check if the script is an
ld+json. This is slow. - Some pages have multiple
ld+jsonscripts! How do we know which one is a recipe? - Some websites, like
grouprecipes.comdont follow this convention at all.
The solution I came up with was just to start with a basic spider (spider.py). All this does is a basic depth-first search of every link on a website that belongs to the same domain.
To solve problem #1, we can do a little investigation for each website by hand and see if there is a url pattern that designates a reicpe. In our websites.json file, I store this like:
"recipe_prefix": "https://www.allrecipes.com/recipe"
Problems #2 and #3 require solutions on a case-by-case basis. I just had to keep adding checks and refactoring the spider to account for different inconsistencies between websites as I went.
Because crawling the websites is a long-running process prone to interruptions, I set a checkpoint that dumps the entire spider object with internal state to a pickle file. This way we can resume scraping for every 5000 items. The code in this section is pretty bad, but it gets the job done.
Once all of the recipe urls are saved into a file called all_recipes.csv we can scrape them with a simple script using recipe-scrapers.
Cleanup
The initial data is really bad. Out of ~500k recipes, only ~340k will be useful.
The simplest type of cleanup we can do is determine the minimum amount of information required for a recipe to be valid. I settled on:
- title
- source url
- ingredients list
- instructions list
If a recipe does not have None for any of these fields, it will be parsed into a Pydantic model and move on to the curated dataset.
There is a lot of junk in the dataset as well. Once I got the data searchable I tried out some queries of different terms like “Bitcoin” and, well…
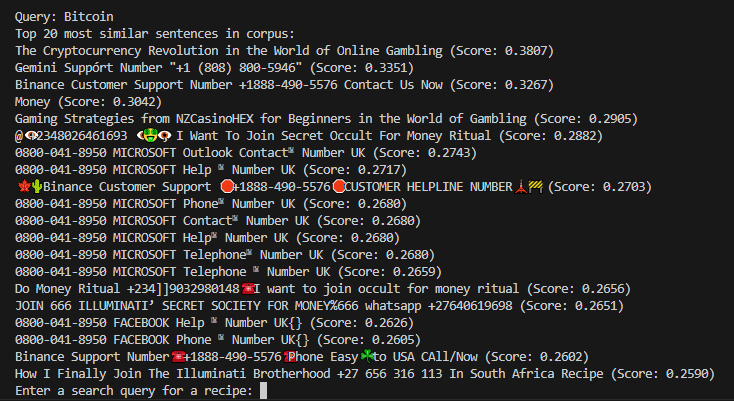
To determine if a recipe was spam or not, I ran an LLM locally using LM Studio. I have never tried self-hosting LLMs, but I was amazed by how easy it was to run a local inference server. I used hermes-3-llama-3.1-8b which fit on my RTX 3070 and runs at about 0.5s/inference. It took about 48 hours to process every single recipe, using 14.4kWh, equivalent to ~1 gallon of gasoline worth of CO2.
Vector Search
This project probably would not have been possible 2 years ago. At least, not for a similar amount of effort. A Python library called SentenceTransformers lets you run pre-trained BERT models on a corpus of text. Getting search on my recipes is as simple as writing a function to turn RecipeData into a string, and then feeding those strings into a model. The resulting tensor is just a list of vector embeddings of each recipe string. Here is what search looks like after the embeddings are generated:
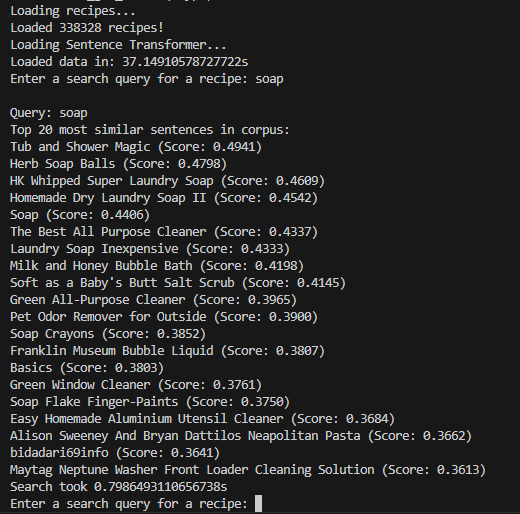
Why did I use a non-food example query for all of these images?
It takes 45s to load the recipes and full-precision vector embeddings, 4GB RAM to hold it all in-memory, and 790ms to retreive 20 results. This is not ideal performance, but it provides a decent starting point for a self-hosted app.
Optimizations
Sqlite DB
The first thing we can do is stop storing our recipes in memory. Uncompressed our recipes take up almost 1GB. We can store all the recipes in a dead-simple sqlite table. Column 1 will be the recipe id, column 2 will be a JSON of the dumped Pydantic model.
The result is less than 100 lines of code I am using the repository pattern to abstract away the details of the data storage. This way hackers can choose if they want to store their recipes in-memory in json or on-disk in sqlite. All they need to do is switch the class they use.
Vector Precision
Our vectors are made up of 384 32-bit numbers by default. This post was at the top of Hackernews the same day I was working on the vector embeddings. According to this post, you can get really good similarity scores even just binary-precision vectors. So instead of [float32, float32] we can use [0, 1] and have similar performance (~96-97% accuracy).
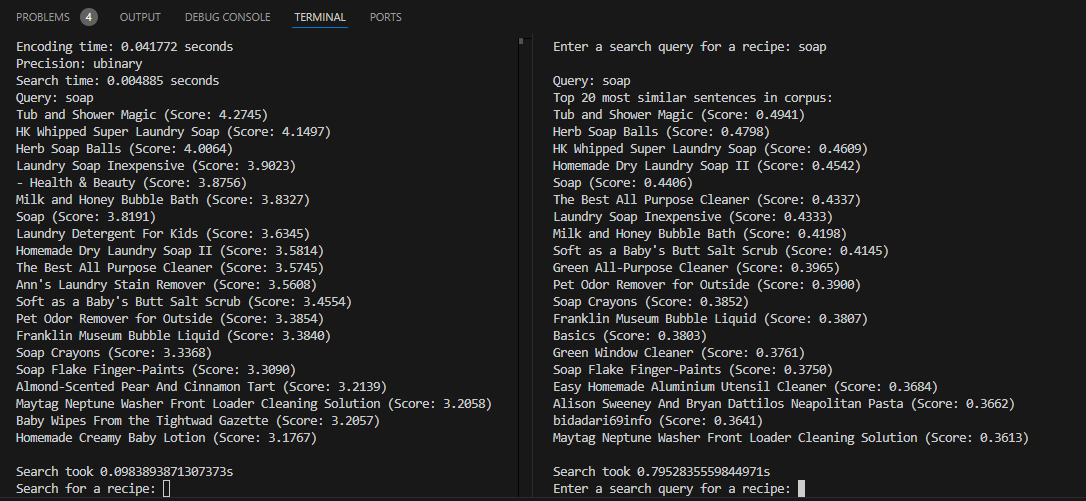
With binary precision, our vector embeddings are 30x smaller, and comparisons run about 100x faster. Our search quality is degraded, but as long as we give the user the ability to turn on higher-precision when they are self-hosting, I don’t mind the lower performance. My goal right now is to allow for hosting even on smaller hardware.
API
We only have 4 routes.
- ”/” is the default which just shows the search bar
- “/recipe_query/?query=&num_items=” shows a list of items for a given query
- “/recipe/?index=” displays a recipe
- “/recipe/json/?index=” displays the raw json of a recipe
Templating
Our templates are also stupidly simple. 3 templates, the base template, the query_results.html template for displaying a list of recipes, and the recipe_detail.html template for rendering a single recipe. There is not a single line of Javascript, and about 14 lines of in-line CSS ripped from even better *** website
Deployment
I use Caddy to handle https for me. I am not gonna lie, I have no idea how Caddy works, I copied this template. As soon as I am done writing this blog post I am going to educate myself about how Caddy works but right now I just want to get this shit hosted.
Note:
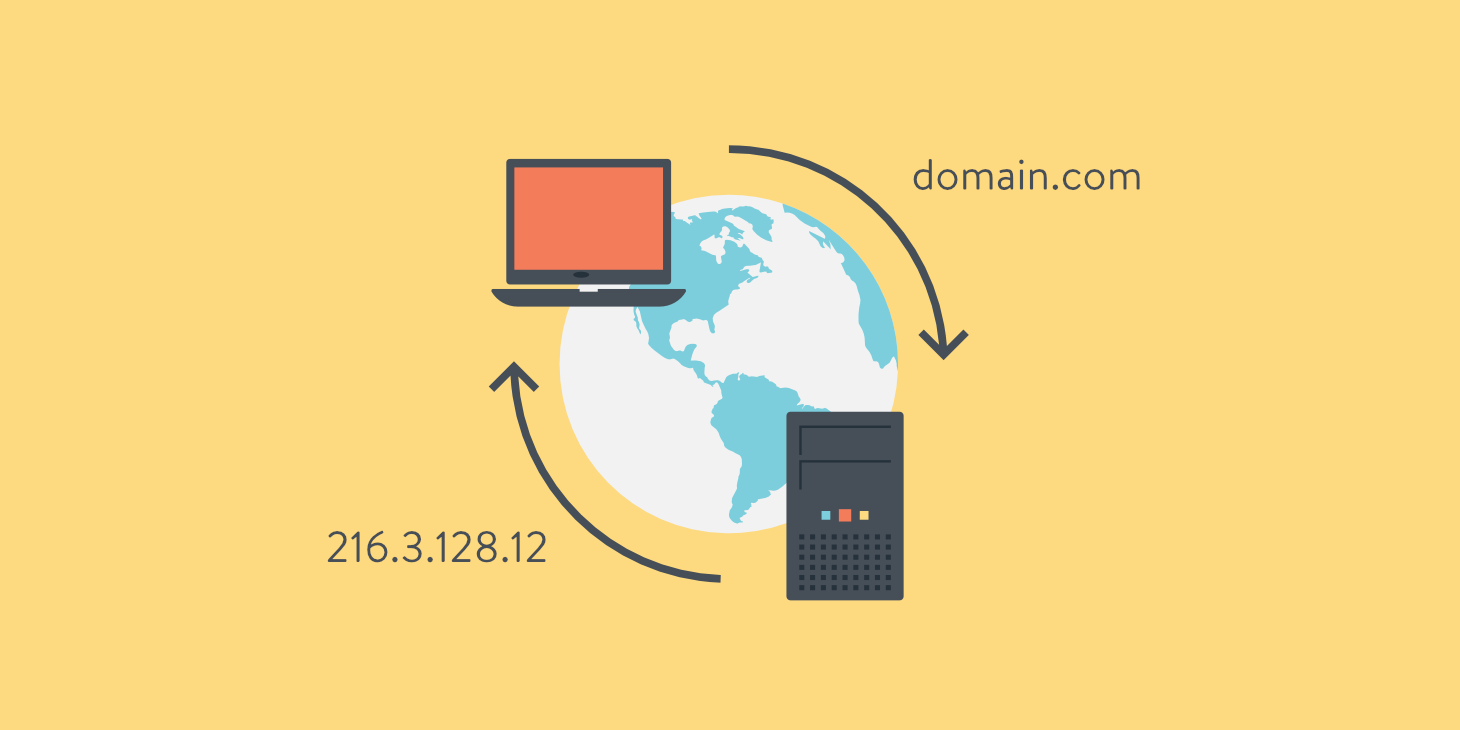
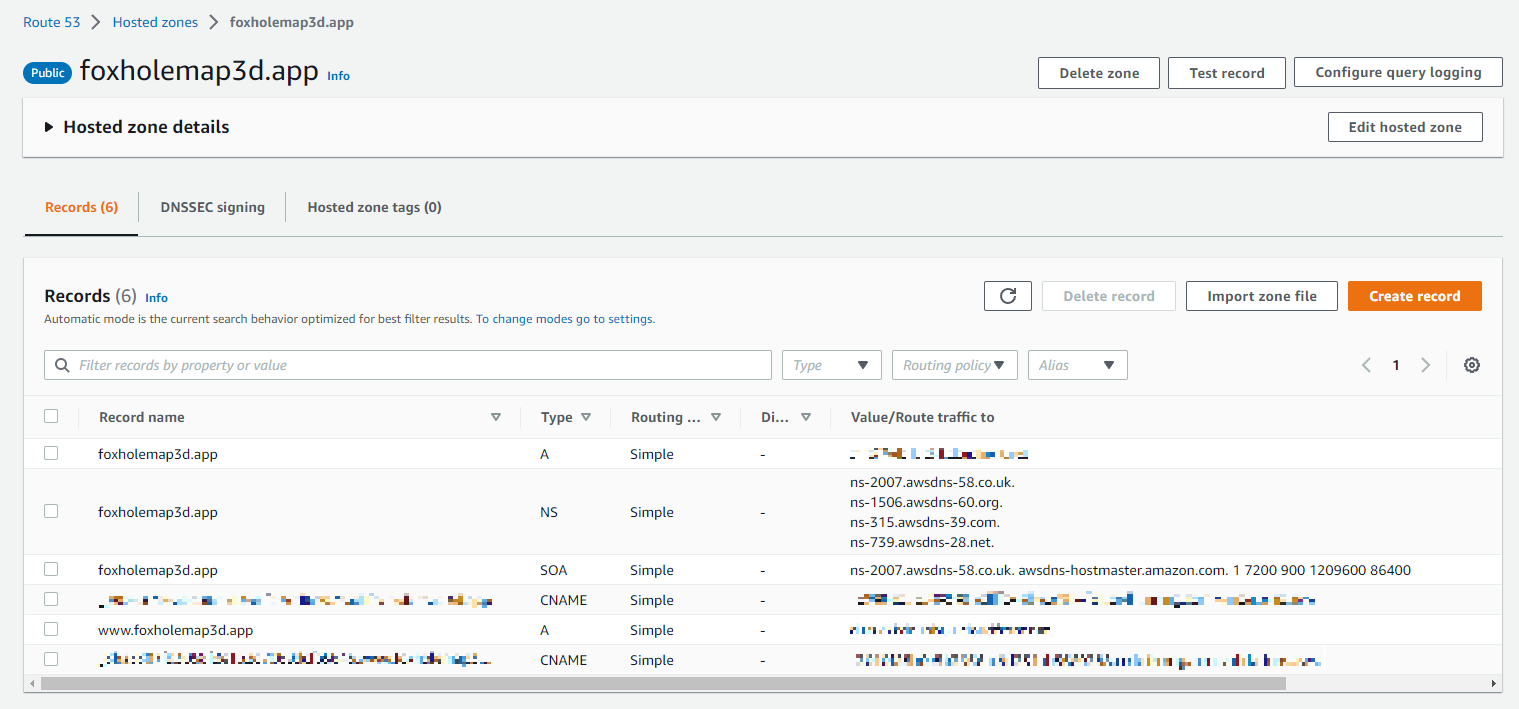
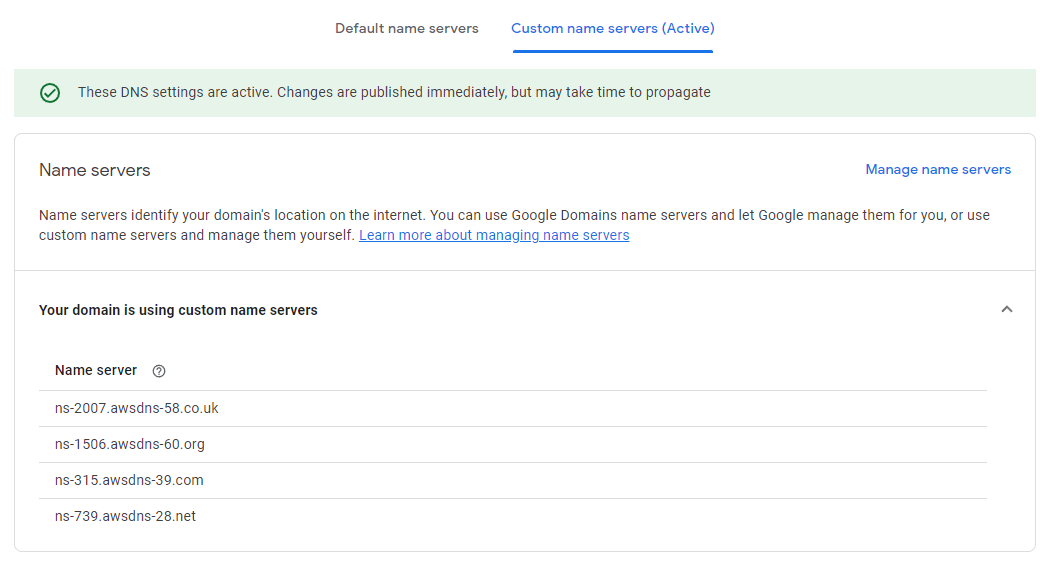
Google migrated all of my domains to Squarespace earlier this year. Fine, whatever, this is the state of tech in 2024. I initially bought the domain hari-recipes.com on Squarespace, just to keep all my domains in one place. Bad idea. Squarespace was not updating my A record to DNS servers. It would not let me use custom nameservers, so I could configure my records elsewhere and it would not let me unlock the domain to move it to another provider. We’ll see if Mastercard lets me chargeback for this shit because they are quite literally stealing my money by not allowing me to do anything with the domain I paid for. hari.recipes cost me $6 on namecheap, and I was able to set up DNS in AWS Route 53 in about 30 seconds. I have no love for Amazon, but at least their services work.
The current app is running on DigitalOcean’s $6 VM. I tried the $4 option, but 512MB of RAM was just not enough to build all of the Python dependencies.
Load Tests
Thanks to all of our optimization and the simplicity of our app, we should be able to serve a pretty decent number of concurrent users on a small VM. I ran load tests using Locust on my PC. I figure that the relationship between performance on my desktop and the cloud VM should be a linear one.
So the ratio of max concurrent users on my desktop / max concurrent users on the VM, should be the same as query duration on my desktop / query duration on the VM
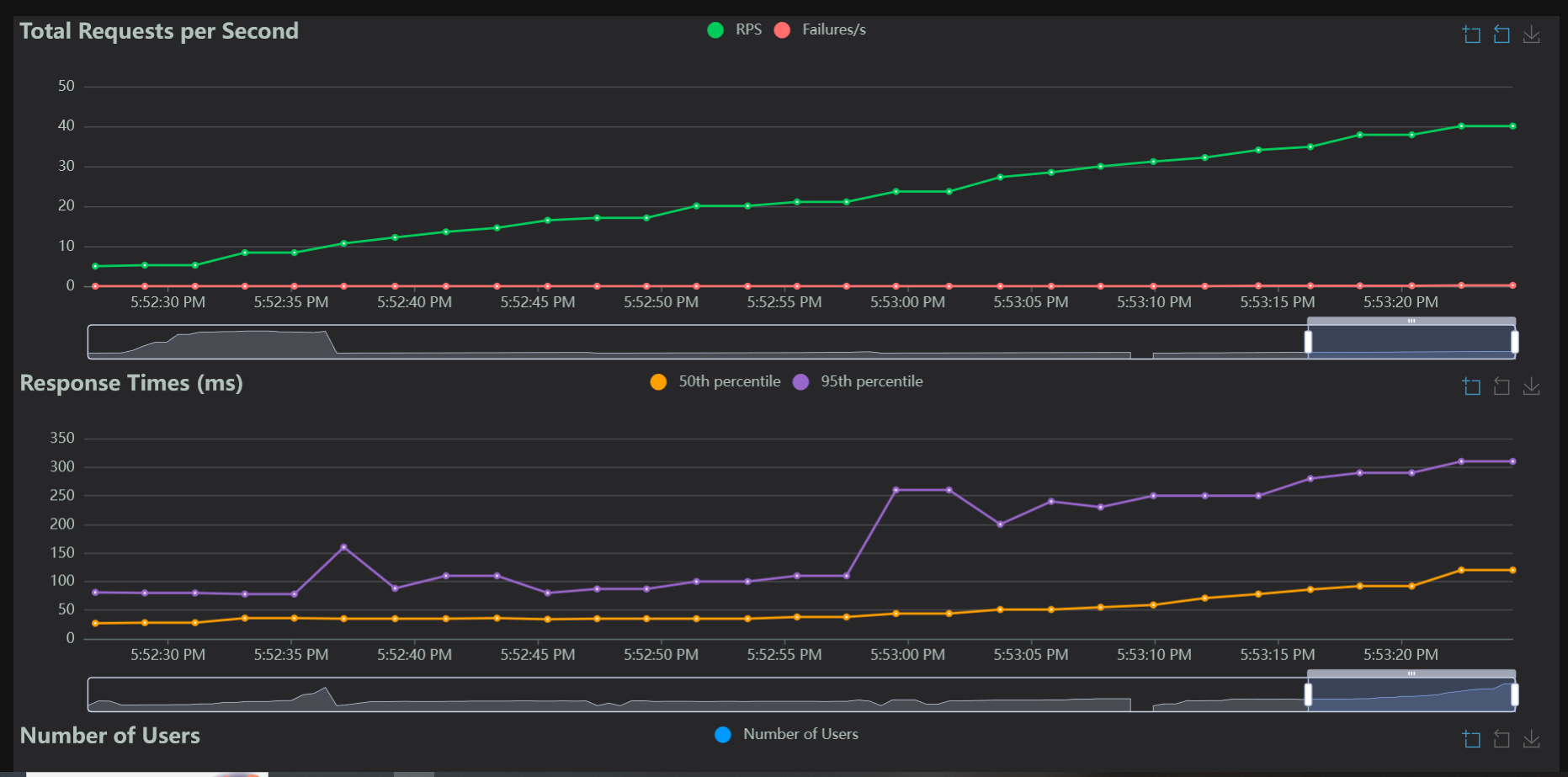
We can see that on my PC, the app can handle about 20 RPS before the 95th percentile response time starts to spike. I didn’t push it as far as it could go, because really I don’t expect many people to use this app, but 300ms resonse is fine for a recipe query.
A query with 250 matches runs in about 0.01 to 0.02s on my machine.

On the VM, the same query runs in 0.04 to 0.08s, so 4x slower.
Based off of my load tests, the VM should be able to handle at least 10 (simulated) concurrent users before response times get up above 300ms. Each of those simulated concurrent users are making query requests once per second. So in reality, a single $6 VM can probably handle significantly more real human users.
Results!
I claimed that this project was built to solve a real problem. Here is my evidence for that claim:

The problem has been solved, the jalapenos have been candied. There are no frameworks to hop between, I can move on with my life.

 A screenshot of “Space Settlers” from CS 4013 at OU
A screenshot of “Space Settlers” from CS 4013 at OU Screenshot of my game written for HTML canvas
Screenshot of my game written for HTML canvas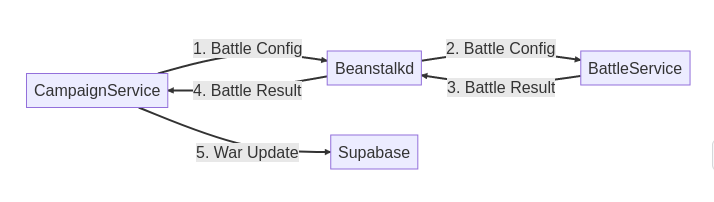 A diagram for those who hate reading
A diagram for those who hate reading











{kind=link}